Drishti Sharma⚠️ Note: This profile is slightly out of date! Last major update: Early '25 I'm currently working as Previously, I spent nearly four years at Clarivate, Noida, working as an Intellectual Property (IP) Researcher and IP Consultant, respectively, analyzing inventions across a wide range of domains — antennas, autonomous vehicles, wireless charging systems, healthcare solutions, user experience technologies (VR, AR and MR), UAVs, and audio systems — all at the intersection of core electronics and AI. |

|
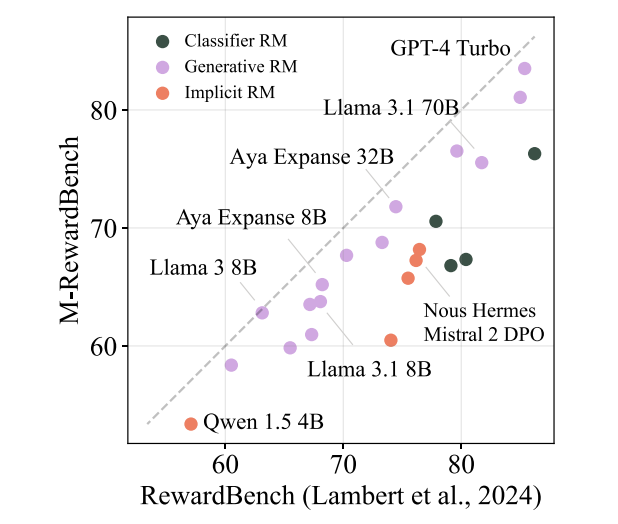 M-REWARDBENCH: Evaluating Reward Models in Multilingual SettingsSrishti Gureja, Lester James V. Miranda, Shayekh Bin Islam, Rishabh Maheshwary, Drishti Sharma, Gusti Winata, Nathan Lambert, Sebastian Ruder, Sara Hooker, Marzieh FadaeeACL 2025 (Main Conference) arxiv / code / This work introduces M-REWARDBENCH, the first large-scale benchmark for evaluating reward models (RMs) in multilingual settings, encompassing 23 languages across 8 scripts and 5 language families. The benchmark evaluates four key capabilities—chat, safety, reasoning, and translation - using 2.87k human-aligned preference instances. A total of 25 reward models, including Classifier, Generative, and Implicit (DPO-trained) types, are assessed. Results show that Generative RMs, such as GPT-4 Turbo, achieve the highest multilingual performance and cross-lingual consistency, with only a 3% average drop compared to English. In contrast, Classifier and Implicit RMs show greater performance declines (~8–13%) and higher volatility, particularly in subjective domains like chat and safety. RM performance is also influenced by translation quality, language resource availability, and script type. 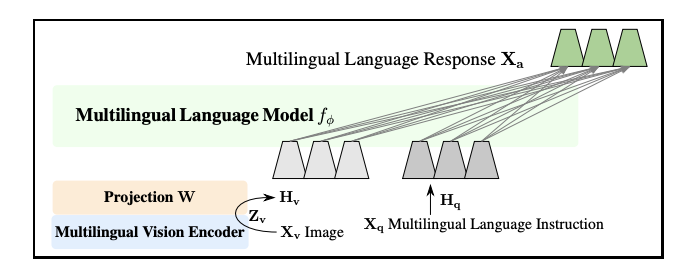 Behind Maya: Building a Multilingual Vision Language ModelNahid Alam, Karthik Reddy Kanjula, Surya Guthikonda, Timothy Chung, Bala Krishna S Vegesna, Abhipsha Das, Anthony Susevski, Ryan Sze-Yin Chan, S M Iftekhar Uddin, Shayekh Bin Islam, Roshan Santhosh, Snegha A, Drishti Sharma, Chen Liu, Isha Chaturvedi, Genta Indra Winata, Ashvanth.S, Snehanshu Mukherjee, Alham Fikri AjiVLMs4ALL Workshop @ CVPR 2025 arxiv / code / This work introduces Maya, an open-source multilingual VLM designed to improve performance in low-resource languages and culturally diverse contexts where existing VLMs often underperform. Maya is built on two key contributions: a multilingual image-text pretraining dataset comprising 4.4 million samples across eight languages—English, Chinese, French, Spanish, Russian, Hindi, Japanese, and Arabic—generated using a hybrid translation framework that integrates Aya 35B, BLEU/N-gram scoring, and balanced sampling from the LLaVA dataset; and a multilingual multimodal architecture that replaces CLIP with SigLIP as the vision encoder for better multilingual adaptability and variable patch size support, while using Aya-23 8B as the LLM, which supports 23 languages and an 8K context window. Visual features are aligned with language space via a 2-layer MLP with GELU activation, following techniques from LLaVA 1.5. Maya outperforms PALO-7B on LLaVA-Bench-In-The-Wild. 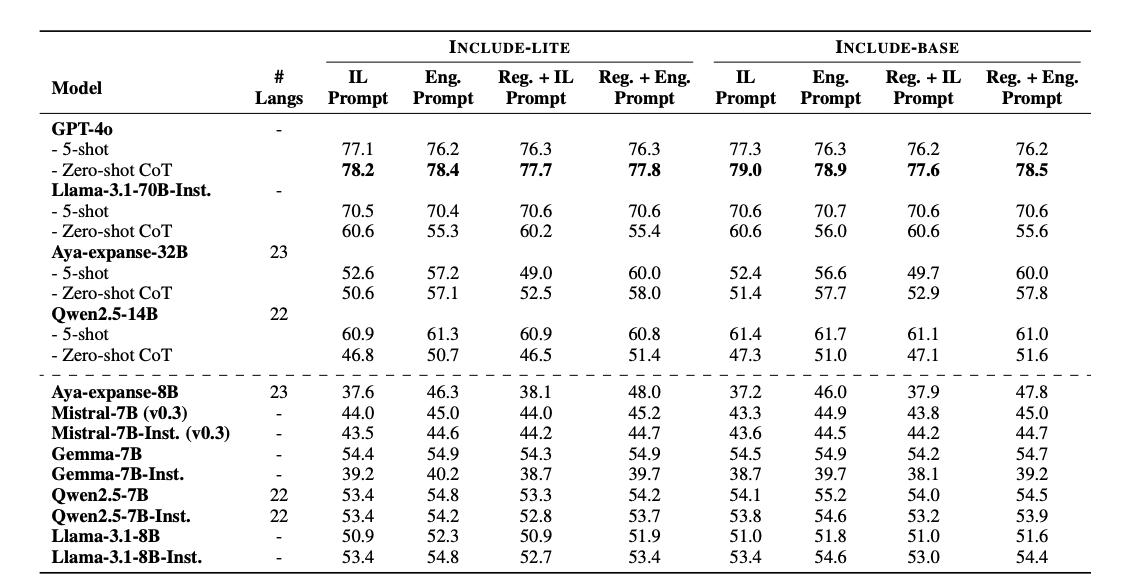 INCLUDE: Evaluating Multilingual Language Understanding with Regional KnowledgeAngelika Romanou, Negar Foroutan, Anna Sotnikova, Zeming Chen, Sree Harsha Nelaturu, Shivalika Singh,......,Drishti Sharma,....., Marzieh Fadaee, Sara Hooker, Antoine BosselutICLR 2025 (Spotlight) arxiv / This work introduces INCLUDE, a multilingual benchmark developed to assess LLMs on regional knowledge and cultural grounding across 44 languages and 15 scripts. Comprising 197,243 MCQs derived from 1,926 real-world exams conducted in 52 countries, the benchmark spans domains such as law, history, culture, and GK. INCLUDE is organized into two subsets: INCLUDE-BASE, which is comprehensive and large-scale, and INCLUDE-LITE, a lightweight version suitable for smaller models or quicker evaluations. The benchmark evaluates a variety of LLMs, including GPT-4o, GPT-3.5, Claude, Gemini, Mistral, Yi, and others. Among these, GPT-4o demonstrated the highest overall accuracy, though all models showed significant performance drops in underrepresented languages and non-Latin scripts. Notably, altering the prompt language or applying instruction tuning had minimal impact on performance. 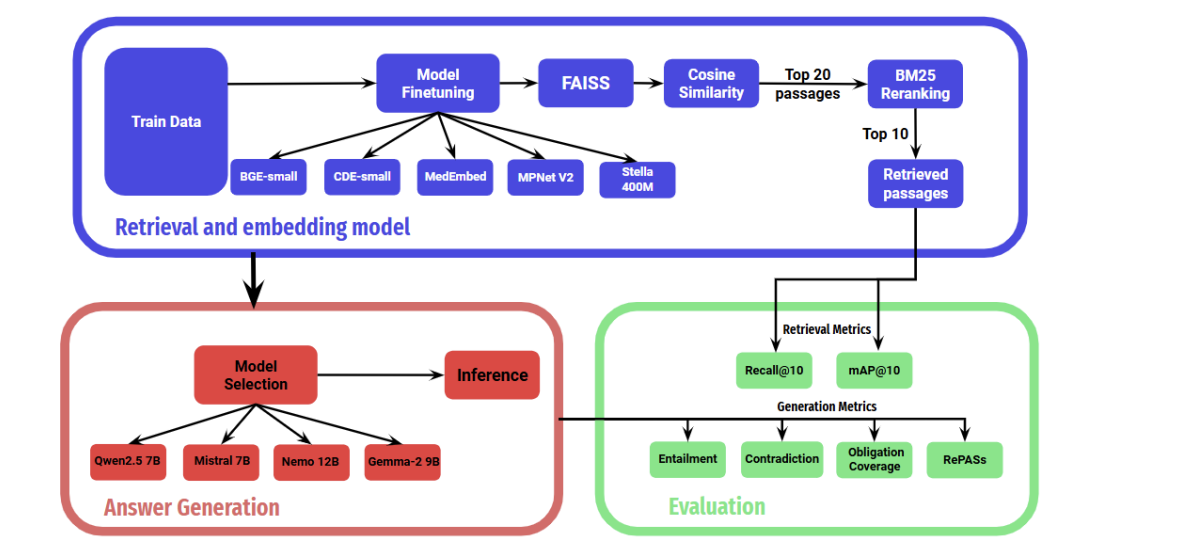 Lexical Reranking of Semantic Retrieval (LeSeR) for Regulatory QAJebish Purbey, Drishti Sharma, Siddhant Gupta, Khawaja Murad, Siddartha Pullakhandam, Ram Mohan Rao KadiyalaCOLING 2025 (RegNLP Track, 4th Place) arxiv / This work introduces LeSeR (Lexical Reranking of Semantic Retrieval), a hybrid retrieval approach that combines dense semantic retrieval—using fine-tuned embedding models on query-passage pairs—with a second-stage reranking via BM25, a classical lexical retrieval method. This decoupled two-stage pipeline enhances both recall and precision, outperforming standalone dense or lexical methods. Multiple embedding models, including Stella, BGE, CDE, and MPNet, were fine-tuned using Multiple Negative Symmetric Ranking (MNSR) Loss, with BGE_MNSR integrated into LeSeR (BGE_LeSeR) yielding the best retrieval performance, achieving Recall@10 of 0.8201 and mAP@10 of 0.6655. For answer generation, the optimal combination was BGE_LeSeR paired with Qwen2.5 7B, attaining the highest RePASs score of 0.4340, reflecting strong performance in entailment, obligation coverage, and minimal contradiction. 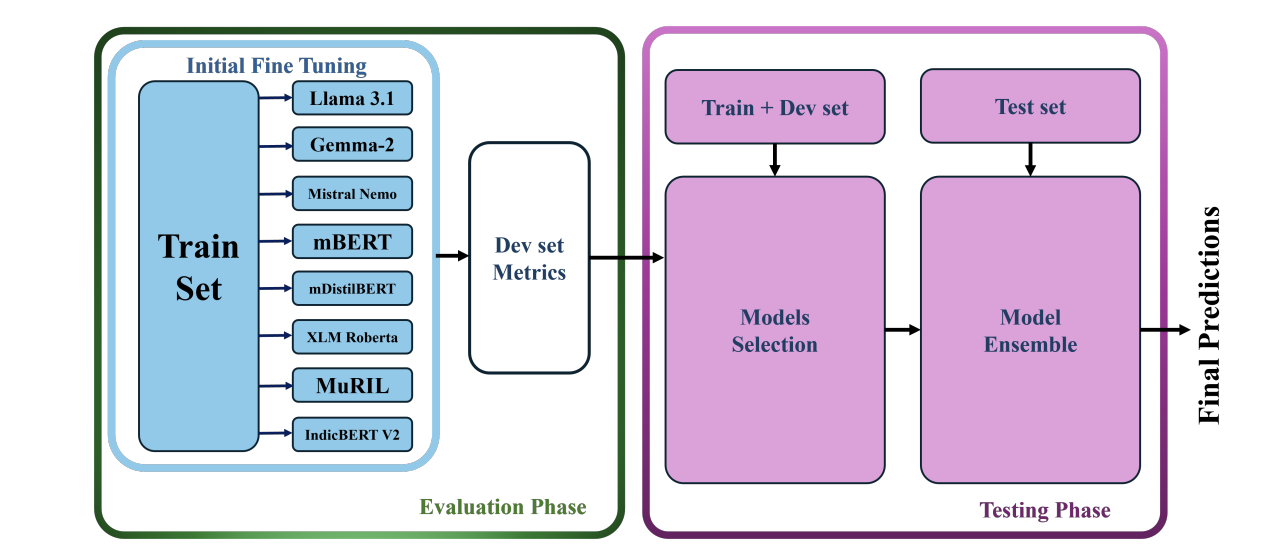 Detection of Language, Hate Speech, and Targets using LLMs in Devanagari ScriptJebish Purbey, Siddartha Pullakhandam, Kanwal Mehreen, Muhammad Arham, Drishti Sharma, Ashay Srivastava, Ram Mohan Rao KadiyalaCOLING 2025 (CHiPSAL Track) arxiv / This work presents a modular multilingual NLP system tailored for five Devanagari-script languages - Hindi, Nepali, Marathi, Sanskrit, and Bhojpuri—targeting three key tasks: language identification, hate speech detection, and hate speech target classification. Each task is addressed with distinct models and strategies: language identification uses an ensemble of fine-tuned IndicBERT V2, MuRIL, and Gemma-2 9B models, achieving high accuracy through majority voting with fallback logic; hate speech detection employs another ensemble combining IndicBERT V2, Gemma-2 9B, and Gemma-2-27B, all fine-tuned using ORPO, with BERT-based models further enhanced by focal loss to handle severe class imbalance; and target classification achieves its best performance using a single Gemma-2 27B model fine-tuned with ORPO, without relying on ensembling. The system achieves F1 scores of 0.9980 for language identification, 0.7652 for hate speech detection, and 0.6804 for target classification. 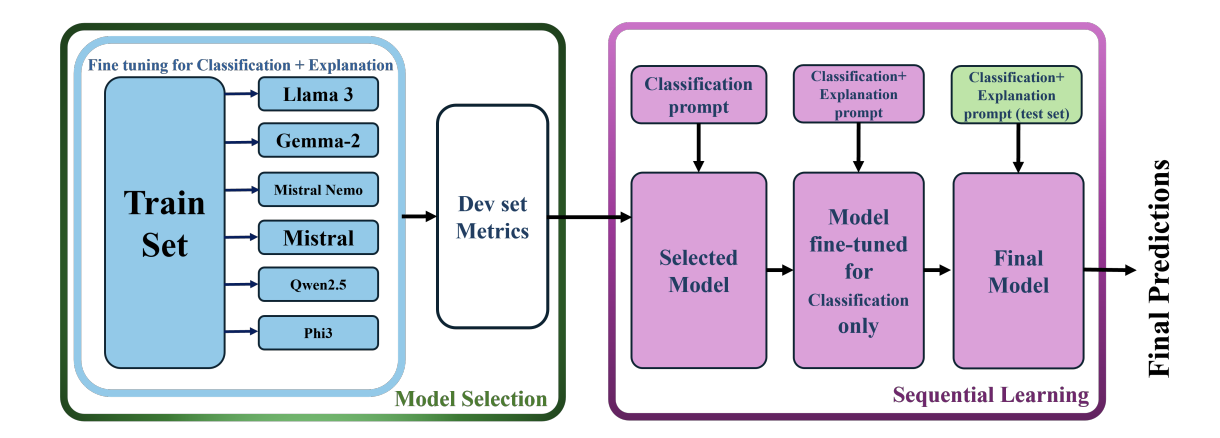 Sequential Learning for Claim Verification and Explanation in Financial DomainsJebish Purbey, Siddhant Gupta, Nikhil Manali, Siddartha Pullakhandam, Drishti Sharma, Ashay Srivastava, Ram Mohan Rao KadiyalaCOLING 2025 (FINLP Track, 3rd Place) arxiv / This work presents SeQwen, a sequential learning-based system, which focused on two tasks: classifying financial claims as True, False, or Not Enough Information (NEI), and generating coherent natural language explanations for these classifications. Using the FIN-FACT dataset, the team evaluated several open-source LLMs, including Qwen2.5, Mistral, Llama3, Gemma-2, and Phi-3. SeQwen employed a two-stage sequential fine-tuning strategy—first fine-tuning for claim classification, followed by joint fine-tuning for classification and explanation generation. This approach consistently outperformed single-stage joint training, with Qwen2.5-7B emerging as the top-performing model. The two-stage method led to a 7.1% improvement in overall score and significantly enhanced explanation quality, while merely increasing joint training epochs offered only marginal gains, underscoring the value of sequential fine-tuning. 
Evaluating Multilingual Vision-Language Reward ModelsShayekh Bin Islam, Dipika Khullar, Gusti Winata, Drishti Sharma, Rishabh Maheshwary, Guneetcode / slides / This work explores the performance and alignment challenges of multilingual vision-language reward models. We introduce Multimodal-RewardBench—a human-annotated, translated benchmark spanning 23 languages—and evaluate both generative and discriminative models in diverse multilingual settings. Our findings reveal inconsistent reward model behavior, greater safety risks in low-resource languages, and performance degradation in visual-linguistic alignment. Discriminative and reasoning-based VLMs show promising potential, particularly in multilingual contexts where standard generative models underperform. 
Adversarial AYA: Multilingual Robustness of Vision-Language ModelsWaseem, Drishti Sharma, Srimoyee, Ahmad Mustafa, Sarthak, Vivek, Manojslides / This project investigates the cross-lingual transferability of adversarial attacks on vision-language models (VLMs). Using a custom multilingual dataset of 6.7K samples spanning six languages (English, Bengali, German, Korean, Russian, Chinese), we test the robustness of models like Aya, Gemma, and PaLI-Gemma against perturbations generated only in English. We implement PGD, MIM, and DIM attacks and evaluate their success using multilingual Sentence-BERT similarity. Results show that English-only attacks transfer effectively to other languages, revealing significant multilingual vulnerabilities in current VLMs and underscoring the need for targeted robustness benchmarks. 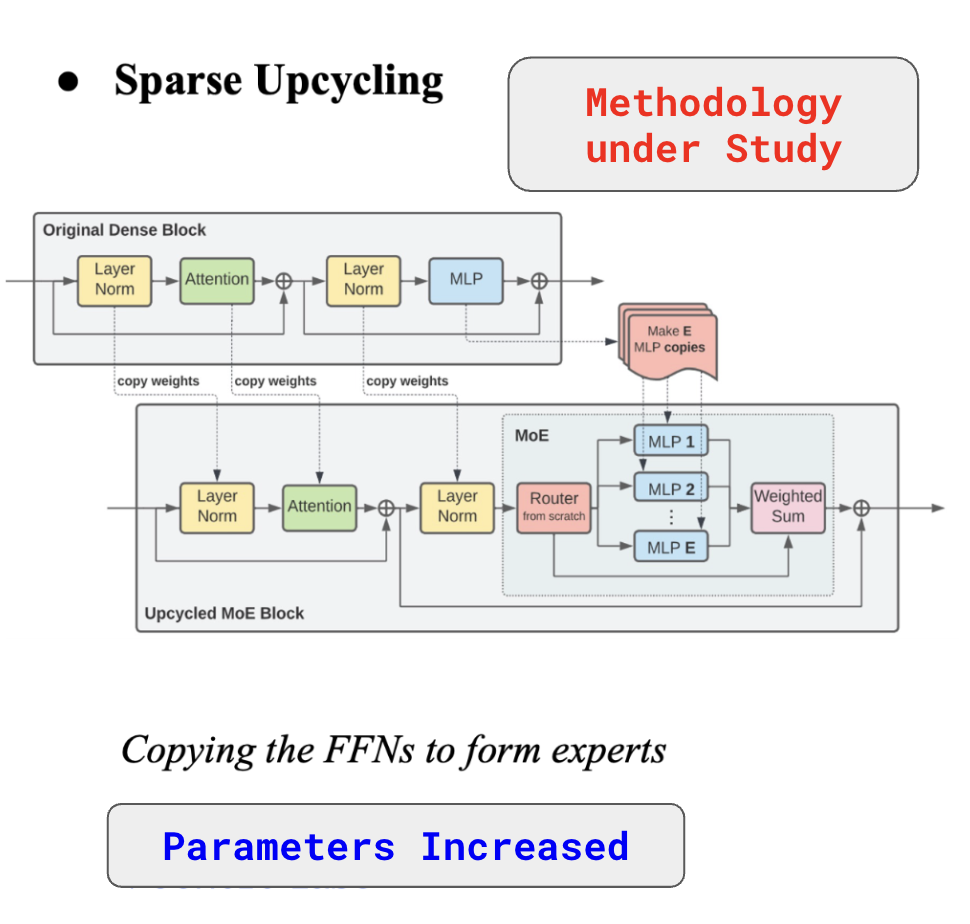
Sparse Upcycling VLMs: Efficient Multilingual Adaptation from Dense ModelsMayank, Trishanu, Alvin, Ahmad, Shivam, Drishti, Alper, Shayekhslides / This project explores sparse upcycling of dense vision-language models (VLMs) as an efficient strategy for multilingual adaptation. Using a parameter-efficient framework, the approach injects lightweight routing into pretrained dense architectures—upcycling both vision encoders and decoder FFNs—without modifying the vision tower. Evaluated on a multilingual dataset of 1.58M samples across 10 languages and 3 domains, the study compares decoder-only, encoder+decoder, and reciprocal upcycling. Results show upcycled small models achieving up to 47.1% win rate against Qwen2-VL-2B with no vision modifications, and demonstrate that decoder-side adaptation drives most of the language lift, while reciprocal tuning improves vision-language alignment. 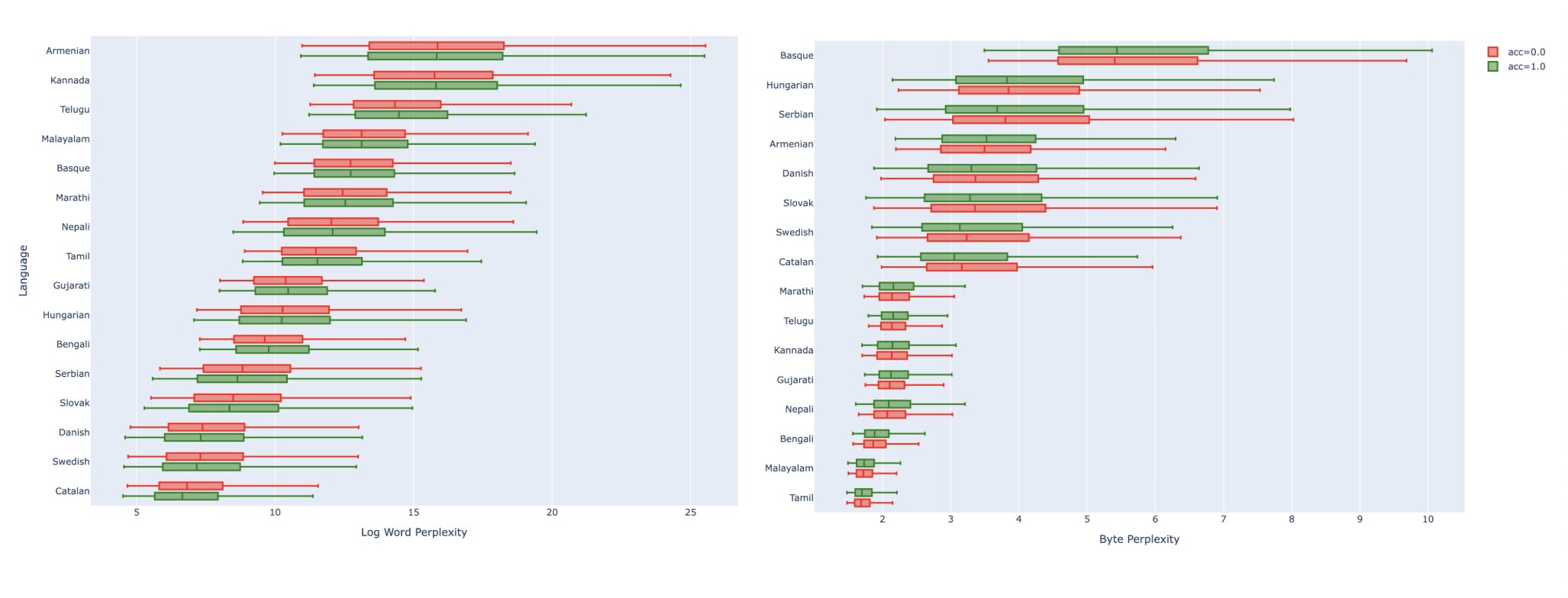
Perplexity vs Evaluation: A Quantitative StudyAflah Khan, Sharad Duwal, Roshan Santhosh, Girish, Shayekh, Drishti Sharma, Henok, Kamya, Nandini, Harshita, Timothycode / slides / This project investigates whether lower perplexity translates into better real-world model performance across tasks like summarization, instruction following, and multilingual QA. We benchmarked over 30 open-source LLMs and found that while perplexity does correlate with performance, the strength of that relationship depends heavily on language. Some models with low perplexity underperform on downstream tasks, especially in underrepresented languages. The results suggest that intrinsic linguistic characteristics and exposure during pretraining affect the connection between perplexity and quality — prompting a call for evaluation beyond perplexity alone. 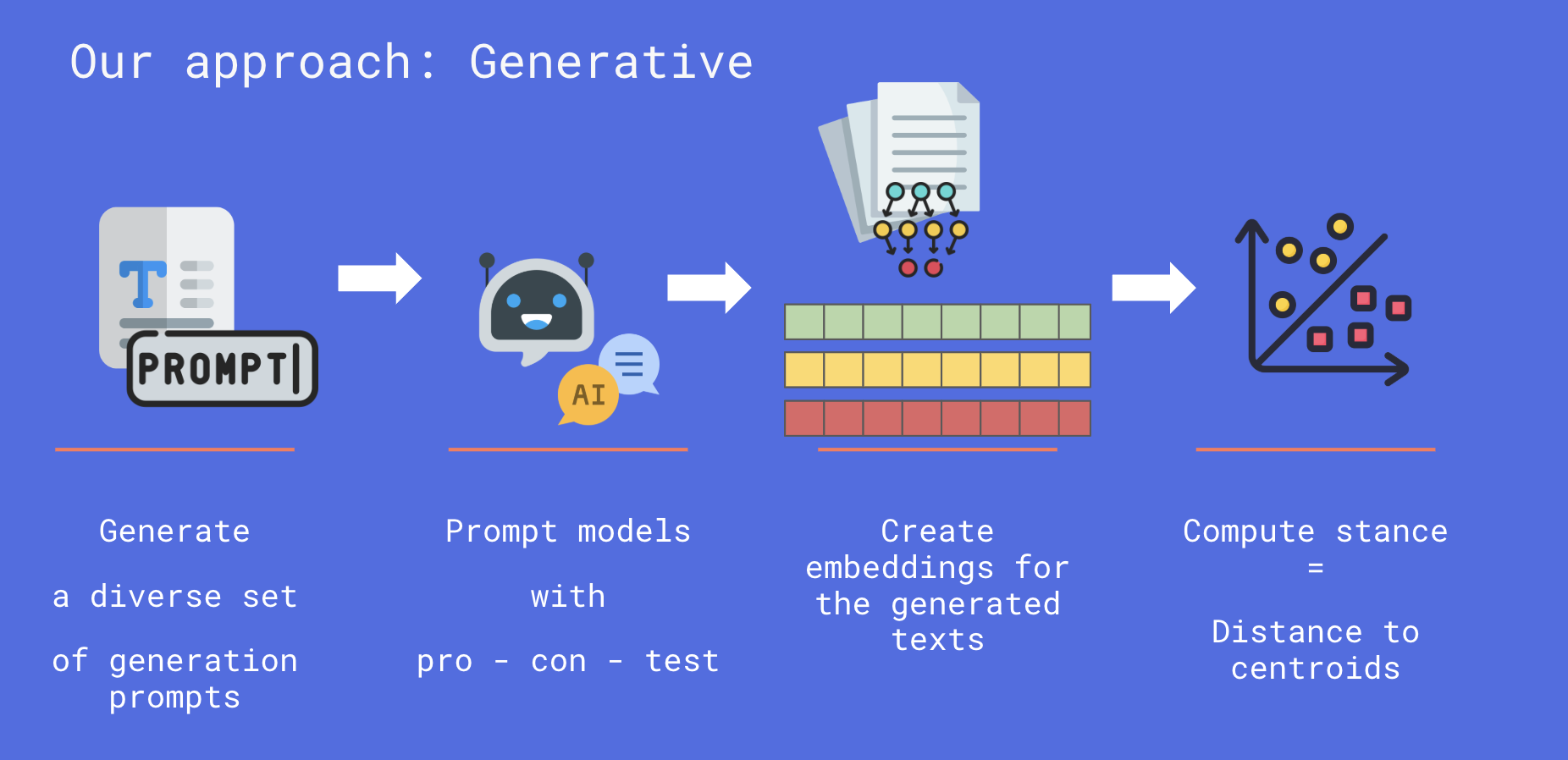
Clash of Civilizations: Exploring Political Bias in LLMs Across LanguagesAlfonso Amayuelas, Manuel Tonneau, Ashay Srivastava, Drishti Sharma, Efstathios Siatras, Antonina Sinelnik, Avneet Kaur, Guneetslides / This work explores political bias in multilingual LLMs using a generative stance evaluation framework. By prompting five open-source models across 10 languages and 12 politically sensitive topics—including AI regulation, nationalism, and public services—we measure how models express stances through generated text. Our findings reveal significant cross-linguistic variability in political leaning, highlighting the limitations of existing bias evaluations and the need for more culturally aware, language-inclusive audits. 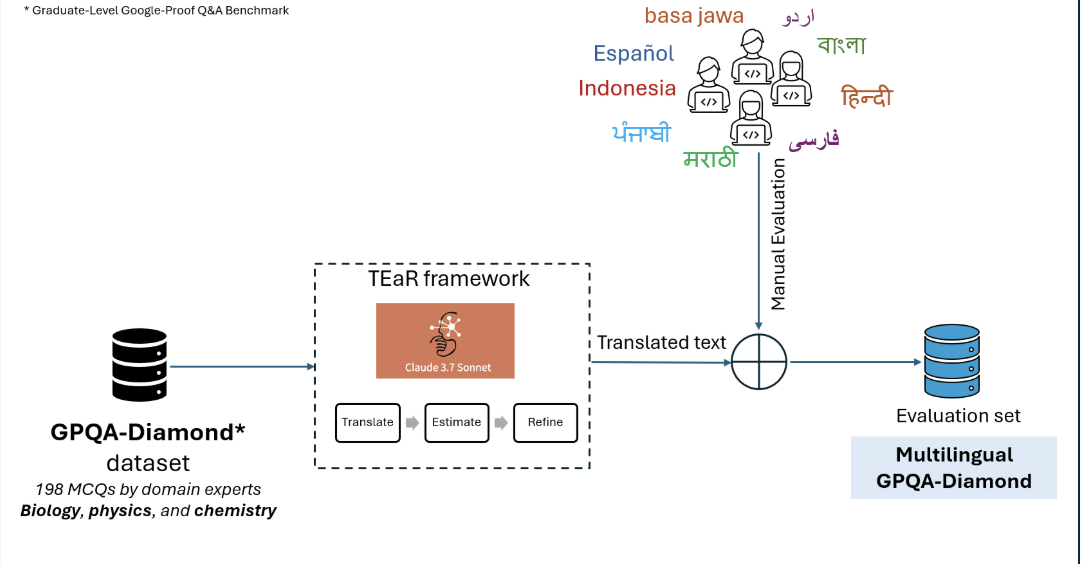
Multilingual Long Chain-of-Thoughts with Small Reasoning ModelsSwati Rajwal, Shayekh Islam, Marek Suppa, Drishti Sharma, Azmine Toushik, Yadnyesh C., Morteza Kashani, Allison Yang, Ira Salsabilacode / slides / This project investigates the performance of small reasoning models on long-form multilingual chain-of-thought (CoT) tasks in scientific domains. Using translated and human-post-edited versions of GPQA, we evaluate models like Qwen3-1.7B and Deepseek-R1-Distill across six languages including Hindi, Bengali, Spanish, and Marathi. Our findings reveal that small models underperform in low-resource languages and generate significantly shorter CoT traces. By fine-tuning models on multilingual reasoning traces derived from CAMEL-AI, we aim to democratize access to high-quality scientific reasoning in non-English contexts. 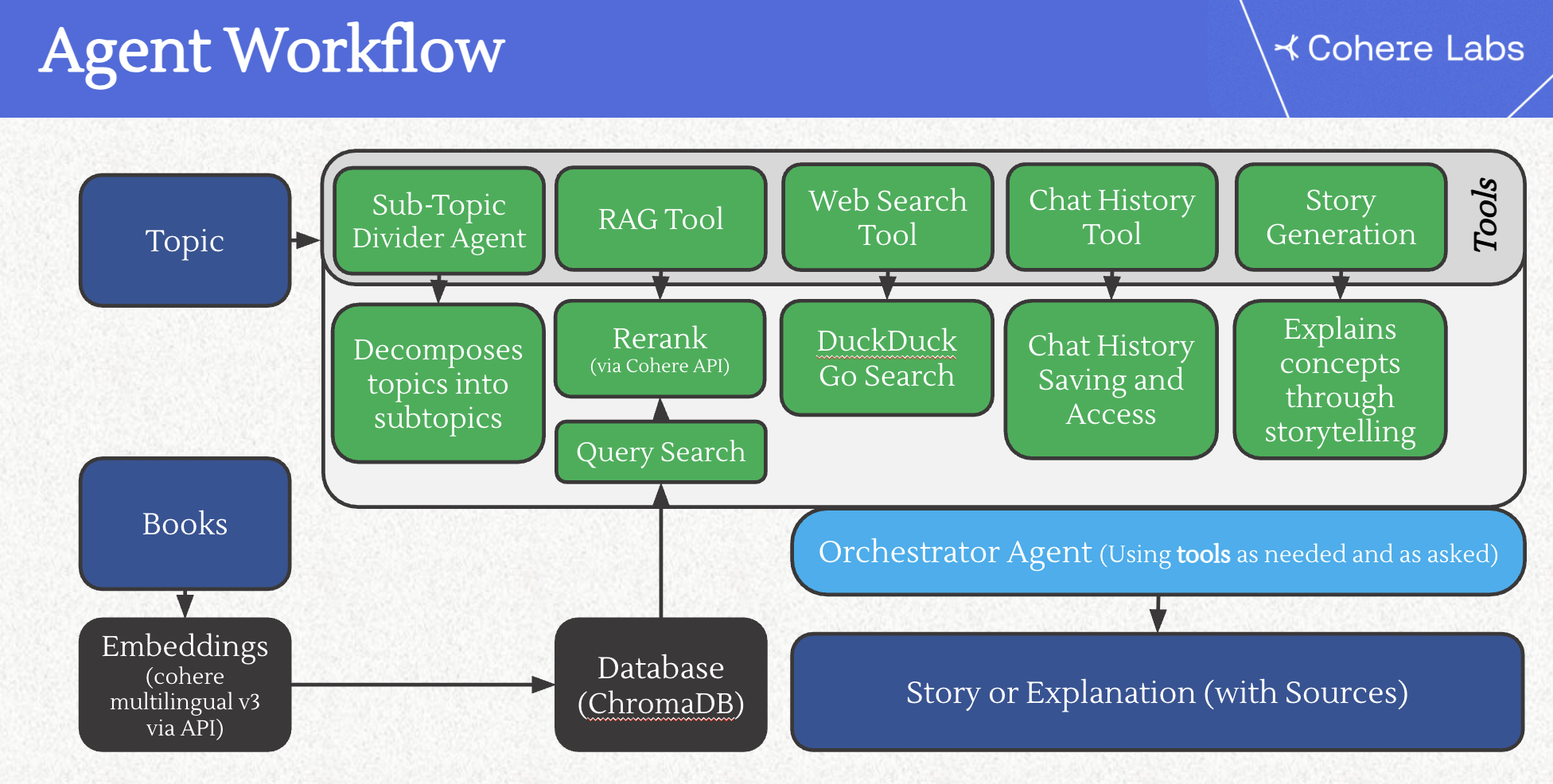
Knowledge Explorer: Education for AllAzmine Toushik Wasi, Mahfuz Ahmed Anik, Wahid Faisal, Drishti Sharmaslides / This project introduces an multi-agent educational assistant designed to deliver personalized, multilingual, and story-driven learning experiences. Built using LangGraph and Cohere’s multilingual embeddings, the system supports topic decomposition, retrieval-augmented generation (RAG), and narrative-based explanations. It breaks down complex subjects into structured subtopics, retrieves reliable content from academic sources, and explains them through engaging, multilingual storytelling. Currently supporting English, Hindi, and Spanish, the agent demonstrates strong baseline reasoning and holds promise for expanding educational accessibility across diverse linguistic and pedagogical contexts. 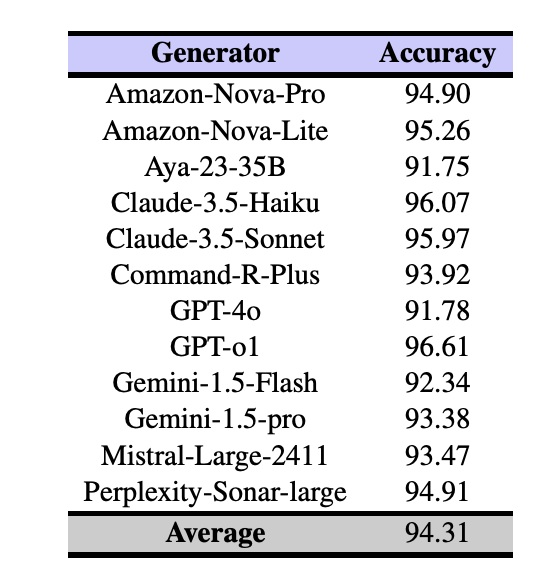
Robust and Fine-Grained Detection of AI-Generated TextsRam Mohan Rao Kadiyala, Siddartha Pullakhandam, Kanwal Mehreen, Drishti Sharma, Siddhant Gupta, Jebish Purbey, Ashay Srivastava, Subhasya TippaReddy, Arvind Reddy Bobbili, Suraj Telugara Chandrashekhar, Modabbir Adeeb, Srinadh Vura, Hamza Farooqarxiv / This work, done in collaboration with Traversaal.ai, presents robust, fine-grained models for detecting AI-generated text in multilingual contexts, trained and evaluated on a large-scale dataset of 2.4 million samples spanning various languages and content domains. The models are designed to distinguish between human- and LLM-generated content, detect subtle patterns in generation style and structure, and function effectively across diverse languages and scripts. Performance is benchmarked in both zero-shot and fine-tuned settings, with analysis of model sensitivity to generation source, prompt format, and language complexity. This research advances the development of reliable defenses against synthetic content in high-stakes multilingual applications. 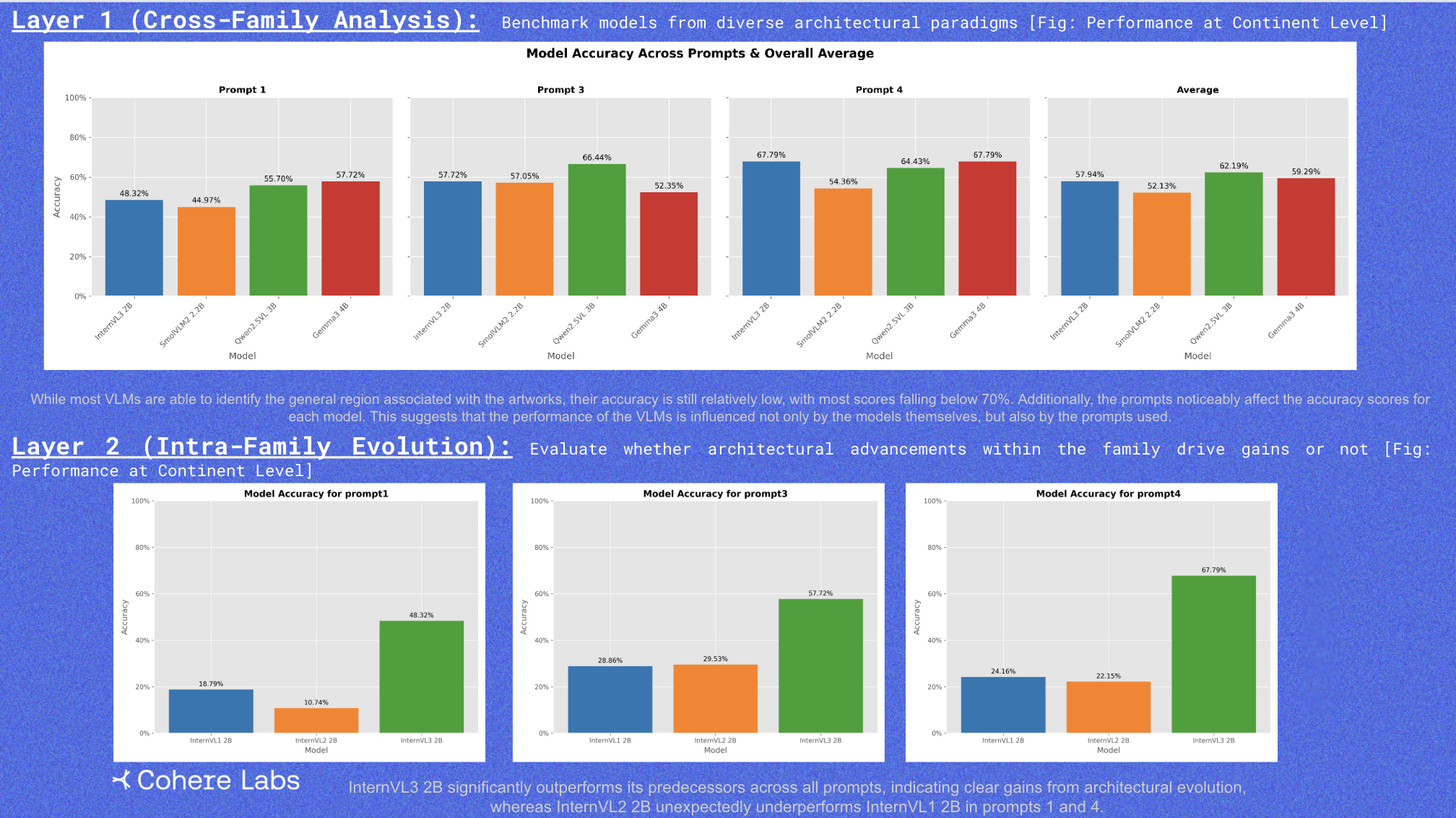
Street Art Analysis and Cultural Mapping with Vision-Language ModelsAlice, Kushal, Drishti Sharma, Hazim, Vatsal, Abigailslides / This project investigates how vision-language models (VLMs) interpret global graffiti through culturally and geographically grounded prompts. The evaluation includes: (1) a cross-family comparison of architectures like InternVL, SmolVLM2, Gemini, and Qwen-VL, and (2) intra-family tracking within the InternVL series. Using prompts translated into five languages (Twi, Hindi, Spanish, Italian, Portuguese), the study explores model accuracy in regional classification, emotional inference, recognition of cultural symbols like Adinkra, and clustering of artists by style. Results reveal inconsistent geographic tagging, limited cultural sensitivity, and challenges in sentiment understanding—highlighting major gaps in VLM interpretability and cultural robustness. 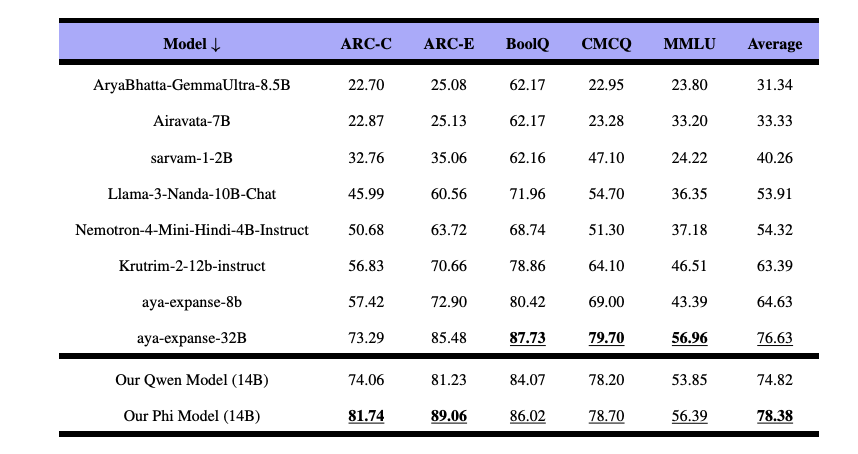
Improving Multilingual Capabilities with Cultural and Local Knowledge in LLMsRam Mohan Rao Kadiyala, Siddartha Pullakhandam, Siddhant Gupta, Drishti Sharma, Jebish Purbey, Kanwal Mehreen, Muhammad Arham, Hamza Farooqarxiv / This research was conducted in collaboration with Traversaal.ai. We fine-tuned seven open-source language models, including Qwen-2.5-14B-Instruct and Phi-4, using 485,000 culturally grounded English-Hindi instruction pairs covering regional norms, idioms, and daily context. The result: up to a 3% average improvement on multilingual benchmarks outperforming even larger models without any architectural changes or vocabulary expansion. Our work shows that lightweight, culturally informed tuning can significantly boost multilingual performance while keeping models efficient. 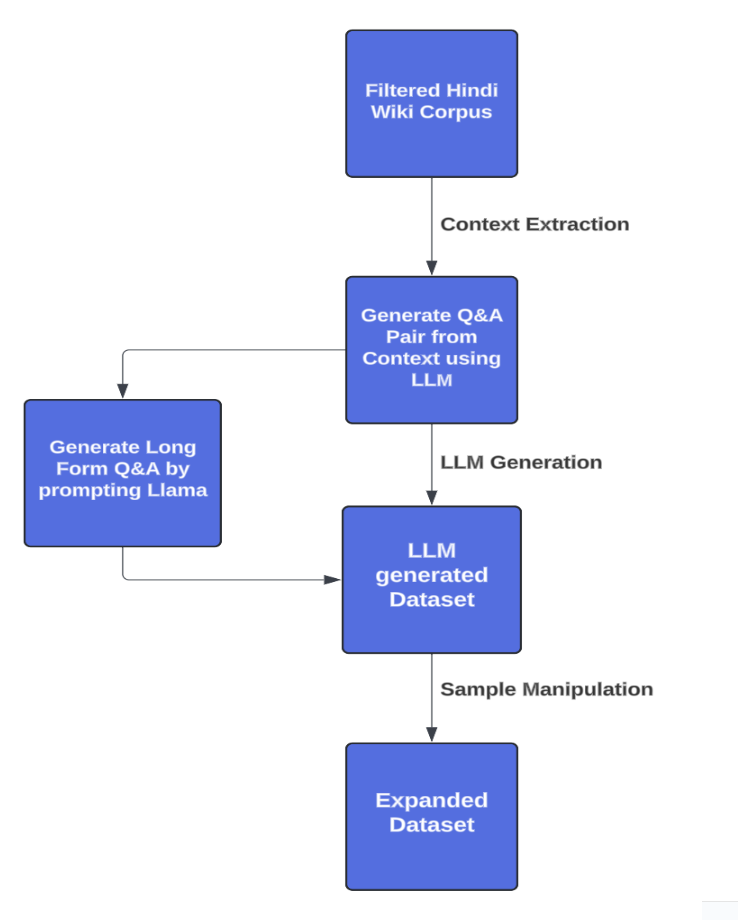
Synthetic Multilingual Instruction Generation for Low-Resource LanguagesDesik, Roshan, Rosemary, Drishti Sharma, Gaurav, Hanifslides / This work presents a scalable method for generating non-licensed, synthetic instruction datasets to support multilingual LLM development, with a focus on Hindi. Through LLM distillation, Wikipedia-based context generation, and FLAN-based translation, we created over 270K high-quality instructions in English and Hindi. Our approach avoids licensed content and is fully open-source to benefit the broader community working on low-resource languages. 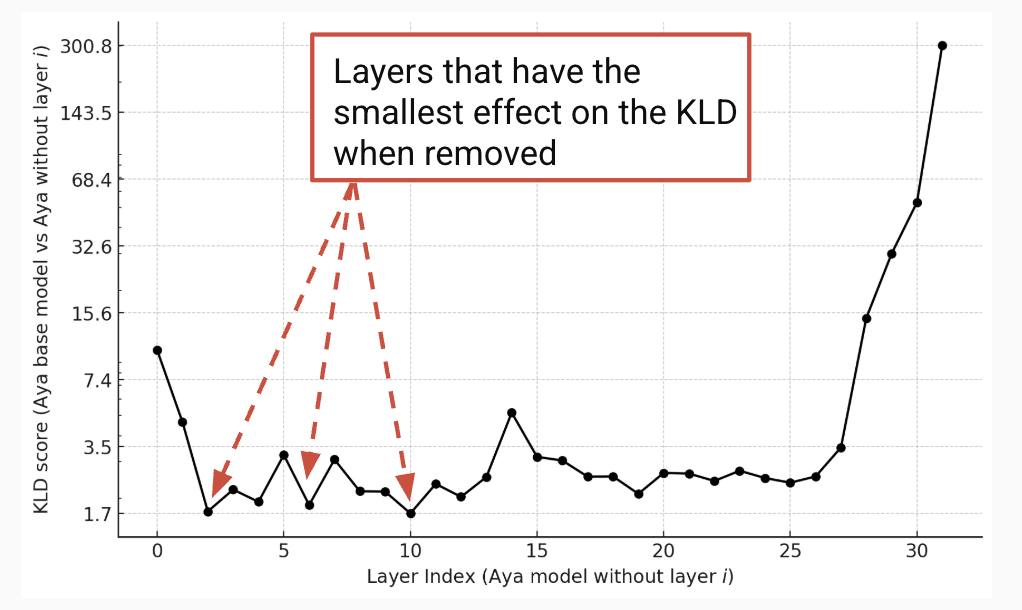
DistAYAGuijin Son, Yaya, Mayank Bhaskar, Shayekh, Ahmad Anis, Vishnu Lanka, Roshan Santhosh, Drishti Sharmaslides / DistAYA addresses the practical challenges of deploying large multilingual language models by focusing on model compression techniques—such as pruning, quantization, and distillation—that aim to improve efficiency without sacrificing performance or linguistic coverage. Centered on the Aya23-8B model, the project systematically explores a range of methods. Among them, SparseGPT, an unstructured and semi-structured pruning technique, proves especially effective—achieving up to 50% sparsity without requiring retraining, using a layer-wise reconstruction approach. The project also evaluates ShortGPT, a layer-pruning method that removes components with minimal impact on output, revealing redundancy in large models. While other strategies like quantization and task-aware distillation are explored, the strongest results come from pruning-based approaches.
|